前言
我曾经花费了一段时间在神经网络程序上,处于兴趣,并使用python和tensorflow实现了一些分类程序,下面是我总结的关于神经网络的肤浅的理解。对于人工智能,只需要会用tensorflow这类现成的工具就行了,普通人不需要真正了解其原理。
概念
人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的
深度神经网络的解释
神经元的基本结构,如下图所示。单个神经元,分别包括输入(p1、p2、p3……)、权重(w1、w2、w3……)、偏置(b),经过线性变换、非线性变换最后得到一个输出值。
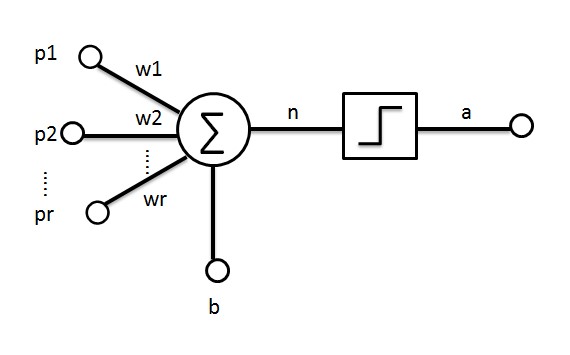
虽然根据不同应用场景,深度神经网络的结构和深度各异,但基本符合神经网络的输入层、隐藏层、输出层结构,而且,目前重点是快速演化以提升模型准确性和效率。所有深度神经网络的输入值,是一套与神经网络表征能力密切相关的信息值。这些值可以是一张图片的像素,也可以是一段音频样本的频率和振幅的数字化表示。 神经网络的层与层之间一般是全连接(FC,也指多层感知器),即第n层的任意一个神经元一定与第n+1层的任意一个神经元相连。虽然DNN从整体上看起来很庞大、复杂,但是从微观的局部模型来说,与感知机是一样,即一个线性关系加上一个激活函数。
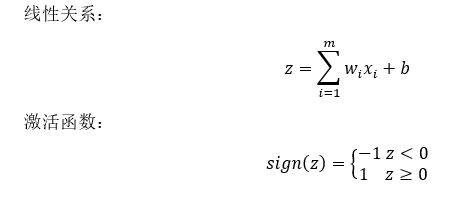
得分函数
f(x,W)=Wx+b
x代表图片像素,W代表权重参数,b是微调参数
若图片有4个像素点,像素值56,231,24,2,将像素点转化为4x1一维矩阵x,而W是一个1x4的矩阵,两者相乘得到一个1x1矩阵,也就是得分值

为图片分类,猫,狗,船。计算每个类别的得分,将W看作w1,计算得到猫的得分值,w2计算得到狗的得分值,w3计算得船的得分值
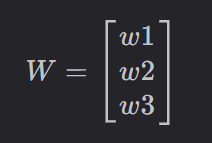
可以得到每个类别的得分,猫得分-96.8,狗得分437.9,船得分61.95

可以看到此分类狗的得分最高,而猫的得分最低,显然是错误的。原因在于当前权重参数矩阵W中的值并不是最合适的参数。 W中的值对于最后的结果产生决定性的影响。一开始可以随机设置W中的参数值,后来迭代过程逐渐改进W中的参数,使得更适合于这些数据去做当前的任务,这也是神经网络整个周期大概做的一件事情。
得分函数的作用
在大多数常见的深度学习模型中,得分函数通常在神经网络模型的最后一层(输出层)发挥作用。得分函数在神经网络中将输入数据转换为输出类别的得分(分数),并将其作为神经网络的输出。得分函数通常采用 Softmax 函数,将神经网络最后一层的输出转换为概率分布。
在训练神经网络时,得分函数用来计算网络输出与真实标签的损失函数,进而反向传播误差和更新网络参数。在测试时,得分函数用于将输入图像的特征与模型中保存的参数进行计算,得到每个类别的得分,并根据得分高低对输入进行分类。
得分函数的选择对神经网络的效果影响很大。如果选择不合适的得分函数,可能导致训练不稳定,甚至不能收敛。常见的得分函数包括 Softmax、SVM(支持向量机)、交叉熵等。根据问题的特点选择合适的得分函数,可以提高神经网络的准确度和鲁棒性。
损失函数
如何衡量分类的结果。有多好或者是多差,用到损失函数,损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。 例子:Multiclass SVM loss损失函数

损失函数损失值越小,分类的效果越好
计算下面分类结果的损失函数值

第1张图片:max(0,5.1-3.2+1)+max(0,-1.7-3.2+1) = 2.9
第2张图片:max(0,1.3-4.9+1)+max(0,2.0-4.9+1) = 0
第3张图片:max(0,2.2-(-3.1)+1)+max(0,2.5-(-3.1)+1) = 10.9
可以看到第二张图片分类效果最好,正确的分类图片,第三张图片分类效果最差,并且分类识别错误
Keras / TensorFlow 中常见损失函数
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
squared_hinge
hinge
categorical_hinge
binary_crossentropy(亦称作对数损失,logloss)
logcosh
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:np.expand_dims(y,-1)
kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
poisson:即(predictions - targets * log(predictions))的均值
cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
非线性与激活函数
上面的神经网络最后的结果是w3(w2(w1x))得到,是否可以有一个矩阵w4=w3w2w1 ,将结果用w4x代替?答案是不可以。神经网络具有非线性的特性,使用非线性函数在每一步矩阵运算之后进行映射。
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。 引入激活函数是为了增加神经网络模型的非线性。无论叠加多少隐层,如果没有非线性激活函数,无非还是个矩阵相乘,不如去掉隐层。 下图为单个神经元输出图示,表示其中的激活函数f(x)作用
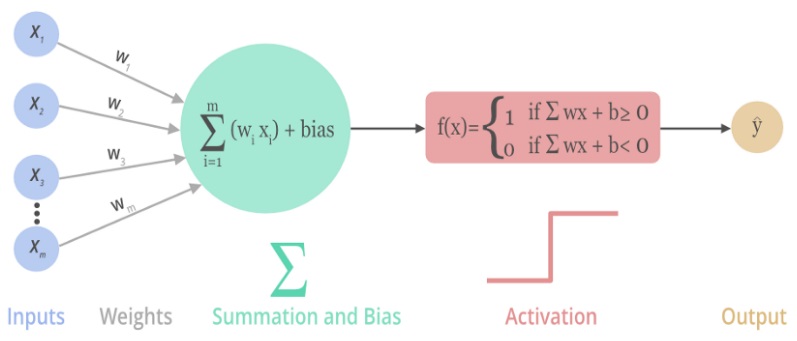
常用的激活函数:
Sigmoid函数、Tanh函数、ReLU函数
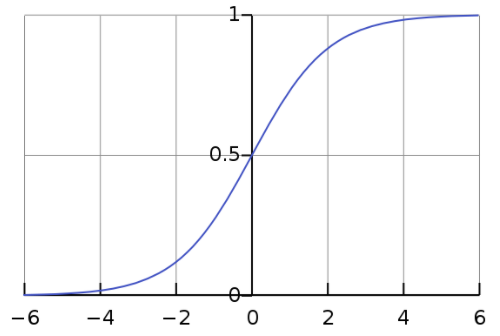
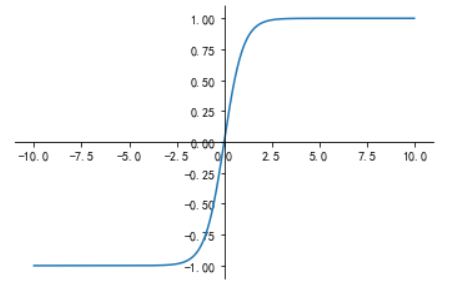
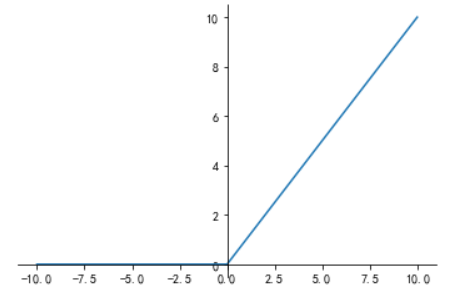
使用max作为激活函数,最后结果就变成了f=w3 max(0, w2 max(0, w1x))
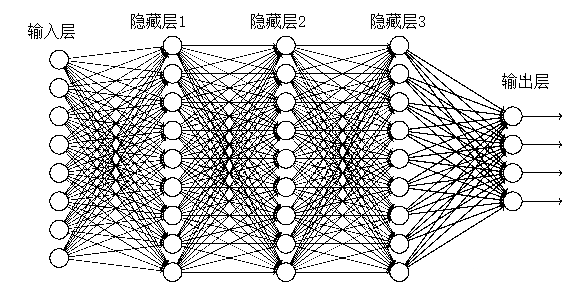
神经网络结构
神经网络图
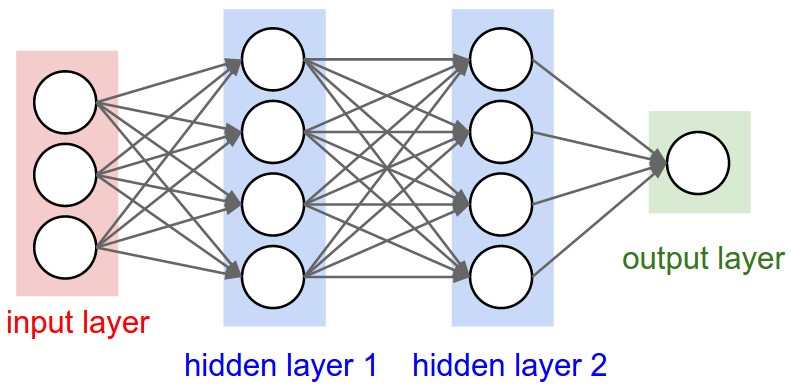 >
>
每个圆圈看作一个神经元 每个神经元都连接到下一层所有的神经元,因此神经网络是全连接的 输入层可以理解为输入数据的特征数 隐层用于提取更多的输入特征,如输入层三个特征代表年龄,身高,体重,隐层1具有四个特征,比如将(年龄0.1+身高0.3+体重0.3)作为第一个特征,(年龄0.2+身高0.4+体重0.5)作为第二个特征…隐层2也是对数据再次进行加工和提取。隐层能够将人类能够认识的特征转化为计算机能够认识的特征。这些特征对于人类是无法理解的,但是对于计算机是更容易分辨的特征。神经网络是黑盒的,中间的数据人类也不知是为什么。 将输入层3x1的矩阵转换成隐层1 4x1的矩阵,需要一个4x3的权重参数矩阵w1与输入层矩阵相乘得到
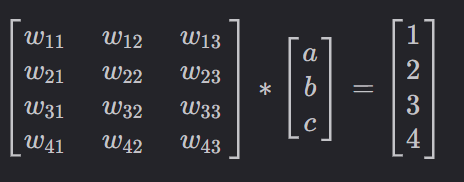
由4x4的矩阵w2与隐层1相乘得到隐层2,由1x4的矩阵w3与隐层2相乘得到最后的输出层结果,结果的好坏程度取决于矩阵w1,w2,w3。神经网络训练过程中,就是找到更好的权重参数适合于当前的任务。
神经网络运行过程
神经网络的运行过程可以分为前向传播和反向传播两个阶段:
前向传播阶段:神经网络从输入层接收数据,经过隐含层的计算,最后输出预测结果。每个神经元都有一个激活函数,用来增加网络的非线性能力。
反向传播阶段:神经网络根据预测结果和真实标签计算误差,然后从输出层到输入层逐层反向传播误差,依次更新权重和偏置,使得网络的预测能力逐渐提高。反向传播算法通常使用梯度下降法或者其变种来优化网络的参数。反向传播算法通过从输出层向输入层反向传播误差,来调整权重参数,使得网络能够更好地拟合数据。
神经网络的层次
神经网络的层次结构分为三大层:输入层,隐藏层,输出层。其中最为重要的是隐藏层,它包括四大部分:卷积层、激活层、池化层、全连接层。
深度神经网络中的"深层"通常指的是具有多个隐藏层的网络。在这里,隐藏层是指除输入层和输出层之外的所有层。如果一个神经网络只包括一个或两个隐藏层,通常不被认为是深度神经网络。然而,一旦网络包括三个或更多隐藏层,它就可以被称为深度神经网络。
人们对神经网络的研究已经超过半个世纪。最初时,人们研究的神经网络通常只有几层的网络,随着研究的深入,特别是深度学习的兴起,深度网络通常有更多的层数,今天的神经网络一般在五层以上,甚至多达一千多层。我们用的神经网络,通常是中间有一个隐层或者有两个隐层。今天,我们所说的深度神经网络指的是什么?直白的说就是用的神经网络隐藏层有很多层,例如,2012年ImageNet 竞赛的冠军模型AlexNet用了8层,2014年冠军模型GooleNet用了22层,2015年冠军模型RestNet用了152 层,2016年多达1207层。
神经网络能够做的事情
神经网络能够做分类,也能做回归。分类和回归的区别在于输出变量的类型上。
通俗理解定量输出是回归,或者说是连续变量预测;定性输出是分类,或者说是离散变量预测。如预测房价这是一个回归任务; 把东西分成几类, 比如猫狗猪牛,就是一个分类任务。
线性回归 —— 连续分布的值(汽车速度,房子高度,房子价格等等)。输入变量与输出变量均为连续变量的预测问题是回归问题;回归最终输出的一般都是一个值。
分类问题 —— 输出变量为有限个离散变量的预测问题成为分类问题;分类最终输出的一般都是一组一组数据,大多为概率。比如有猫狗两个分类,最终输出的可能为0.2/0.8, 代表着预测为猫的概率与预测为狗的概率。