第一步是保存所有markdown格式文章到本地。这一步要手动保存。有的自己没有保存,多数和技术无关。或者是翻译的sfml教程单独保存了。
保存下来的一共613文章。有573个公开的。还有23个公开的早期用富文本编辑器写的,手动复制的md文件。还有3个草稿和14个自己可见的文章。
第二步是把markdown文件里的图片链接全部下载
用粗略技术和问ai,写了一个lua脚本来解析和下载所有md里面图片链接。用法是把目录作为脚本参数,就会自动扫描目录里面的所有md文件并且下载。脚本写的很烂但是完成了任务。
local lfs = require("lfs")
--检查输入参数 目录不需要加斜杠在末尾
local argCount = #arg
if (argCount ==0) then
print("input directory,don't add slashes at the end")
os.exit(0)
end
--检查是有效目录
function dirExists(dirPath)
local attrs = lfs.attributes(dirPath)
return attrs and attrs.mode == "directory"
end
if not(dirExists(arg[1])) then
print("not a valid directory")
os.exit(0)
end
--获取目录下文件名 不递归
local function getFiles(path)
local files = {}
for entry in lfs.dir(path) do
local fullpath = path .. entry
local attr = lfs.attributes(fullpath)
if attr and attr.mode == "file" then
table.insert(files, entry)
end
end
return files
end
--转换md文件
function convert_md(filePath,name)
--读取md内容
local markdown_text = ""
local file = io.open(filePath, "r")
if file then
-- 读取文件内容
markdown_text = file:read("*all")
-- 关闭文件
file:close()
else
print("open file failed!")
os.exit(0)
end
--提取图片地址
local pattern = "%!%[.-%]%((.-)%)"
local image_urls = {}
for url in markdown_text:gmatch(pattern) do
table.insert(image_urls, url)
end
-- 下载提取到的图片地址
for i, url in ipairs(image_urls) do
print(i, url)
local cmd = "wget -c --no-check-certificate -P \""..arg[1].."/converted/resource/"..name.."\" " .. url
os.execute(cmd)
end
end
--建立目标目录
local cmd = "mkdir \""..arg[1].."/converted\""
os.execute(cmd)
cmd = "mkdir \""..arg[1].."/converted/resource\""
os.execute(cmd)
cmd = "mkdir \""..arg[1].."/converted/convertedmd\""
os.execute(cmd)
cmd = "mkdir \""..arg[1].."/converted/finalhtml\""
os.execute(cmd)
-- 获取文件名
local files = getFiles(arg[1]..'/')
for _, fileName in ipairs(files) do
--检查是md结尾的markdown文件
if(string.match(fileName, "%.md$"))then
--去除文件扩展名
local idx = fileName:match(".+()%.%w+$")
if idx then name = fileName:sub(1, idx - 1) end
--创建每个md文件保存图片的文件夹
local cmd = "mkdir \""..arg[1]..'/'.."converted/resource/"..name.."\""
os.execute(cmd)
convert_md(arg[1]..'/'..fileName,name)
end
end
脚本调用wget逐个下载图片。每个md文件的图片独立保存在用名命名的文件夹里面。运行了20分钟。保存了1967张图片和gif。压缩成zip一共是295mb。
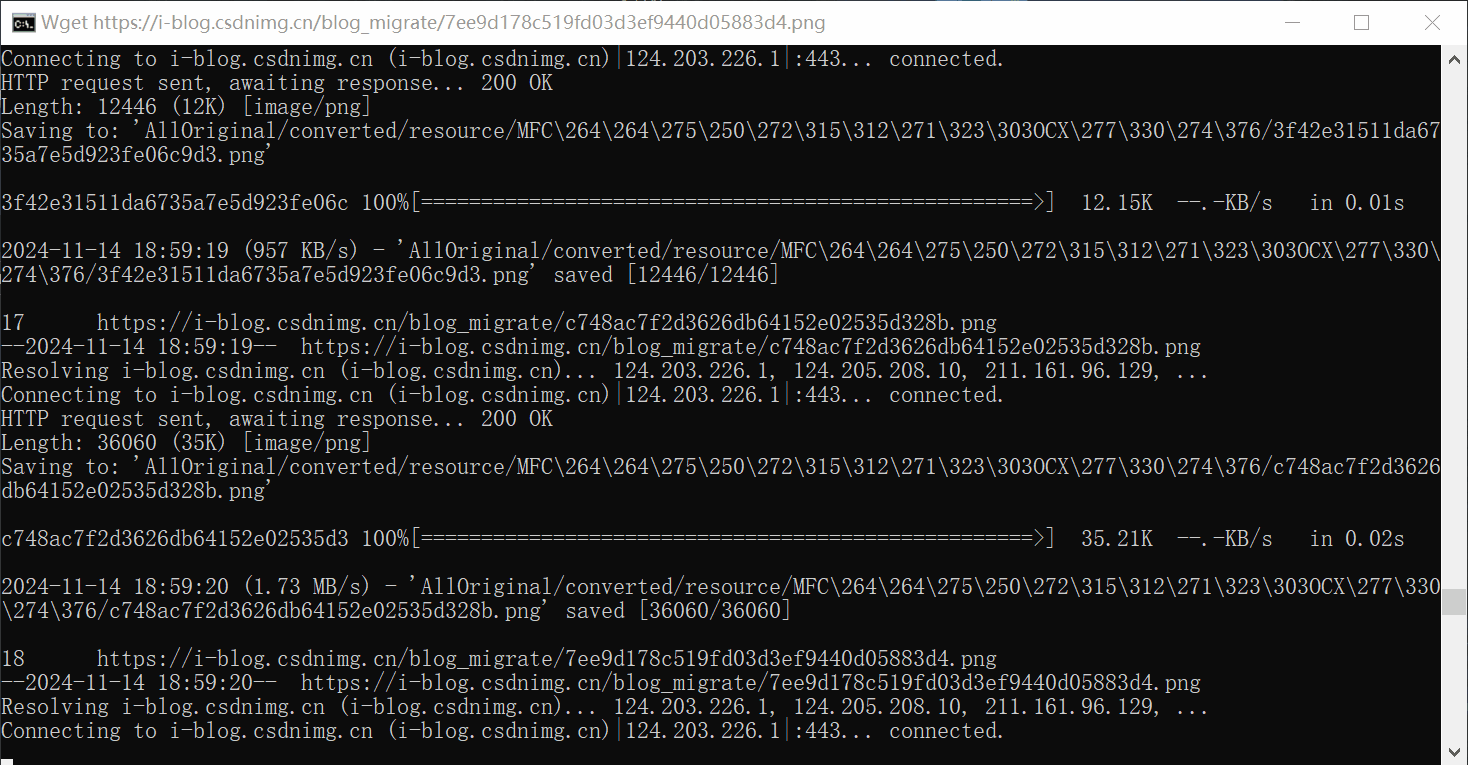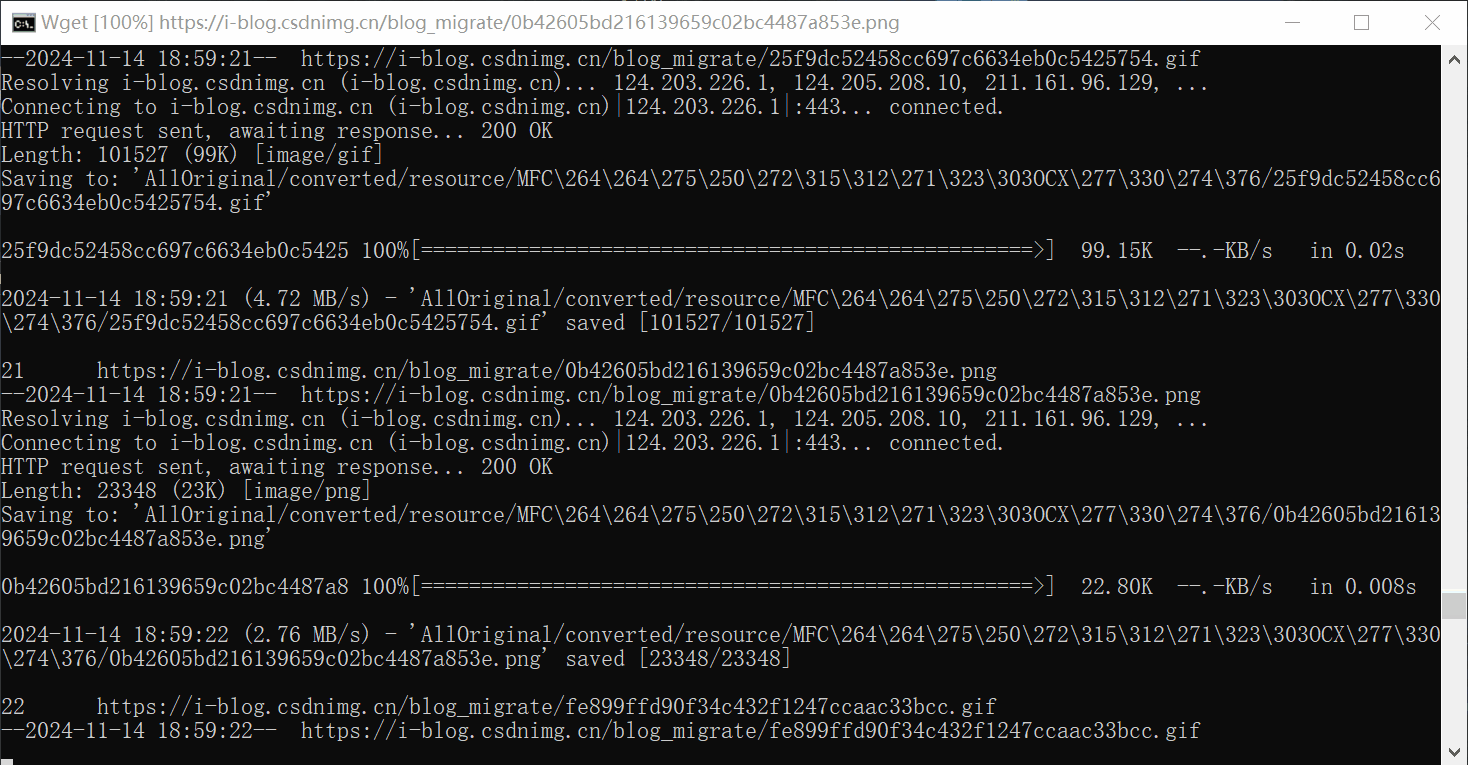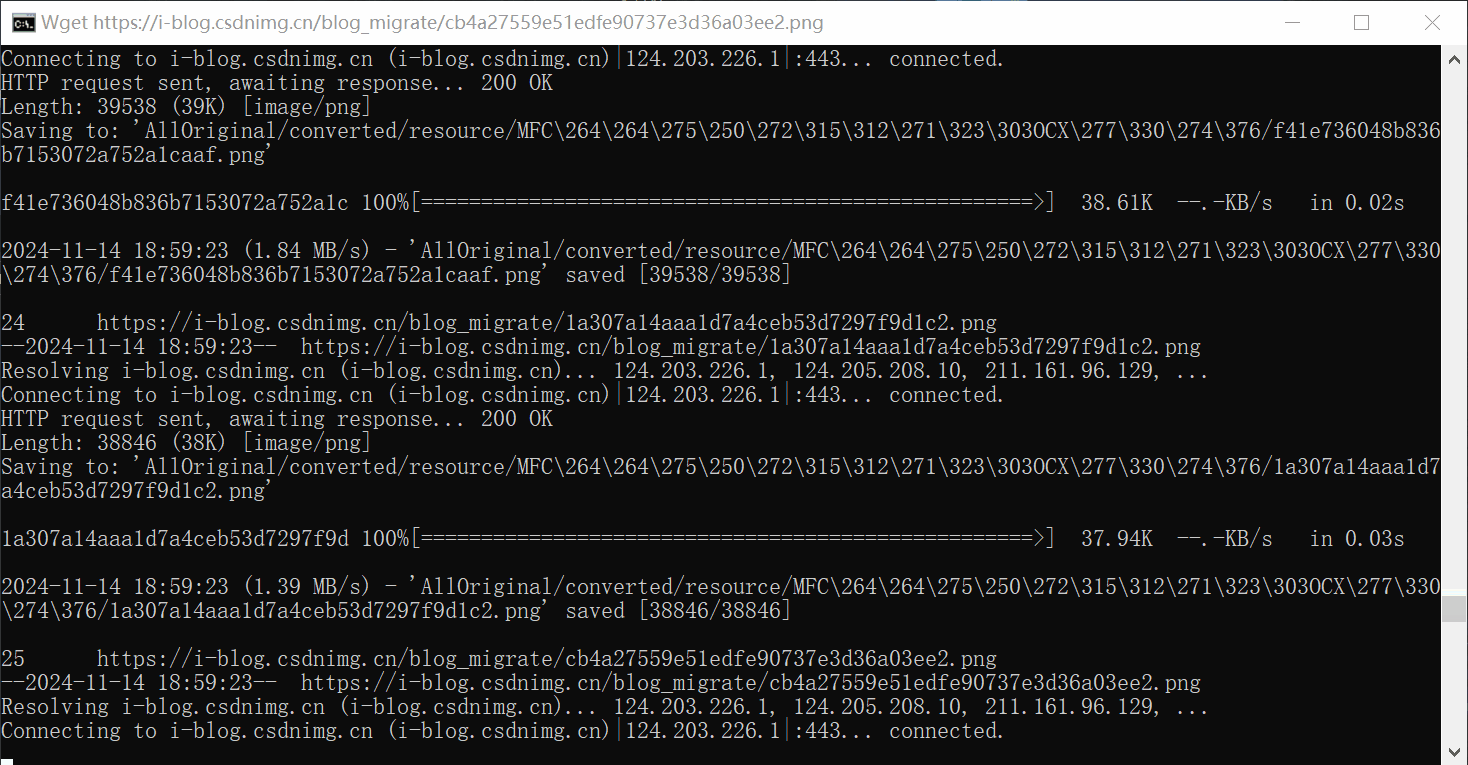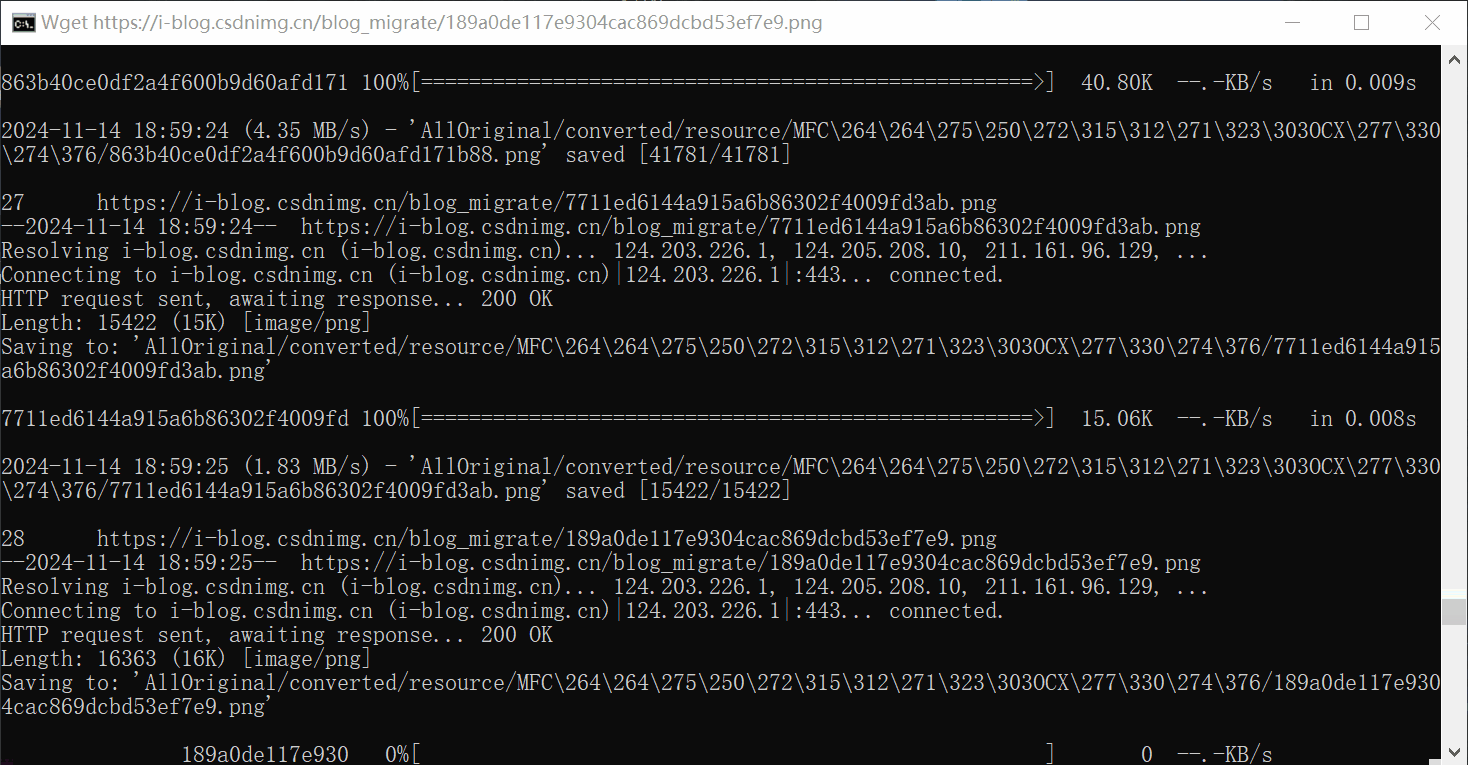
下载后的图片目录,对应每个markdown的文件名
保存的图片
现在第二步完成了。已经可以脱离csdn网站了。
后面两步现在不需要做了。以后用到的时候再做。
第三步做的就是本地化markdown文件里面链接,替换成本地图片路径。实现能够正常浏览
第四步是用pandoc把markdown文件全部转换成html格式并且加上css样式,方便网页浏览。