到https://search.google.com/ ,验证自己的网站之后,可以查看自己网站的收录情况。
但是我的是新的网站,没有收录我的页面,我只想知道我的一个页面是否会被收录,因为我听AI说google的爬虫会执行简单js脚本。但是网页内容我的是js解析markdown动态生成的内容。不知道会不会抓取到真正的内容。
使用这个页面可以得到一些信息。https://search.google.com/test/rich-results,直接输入网站域名
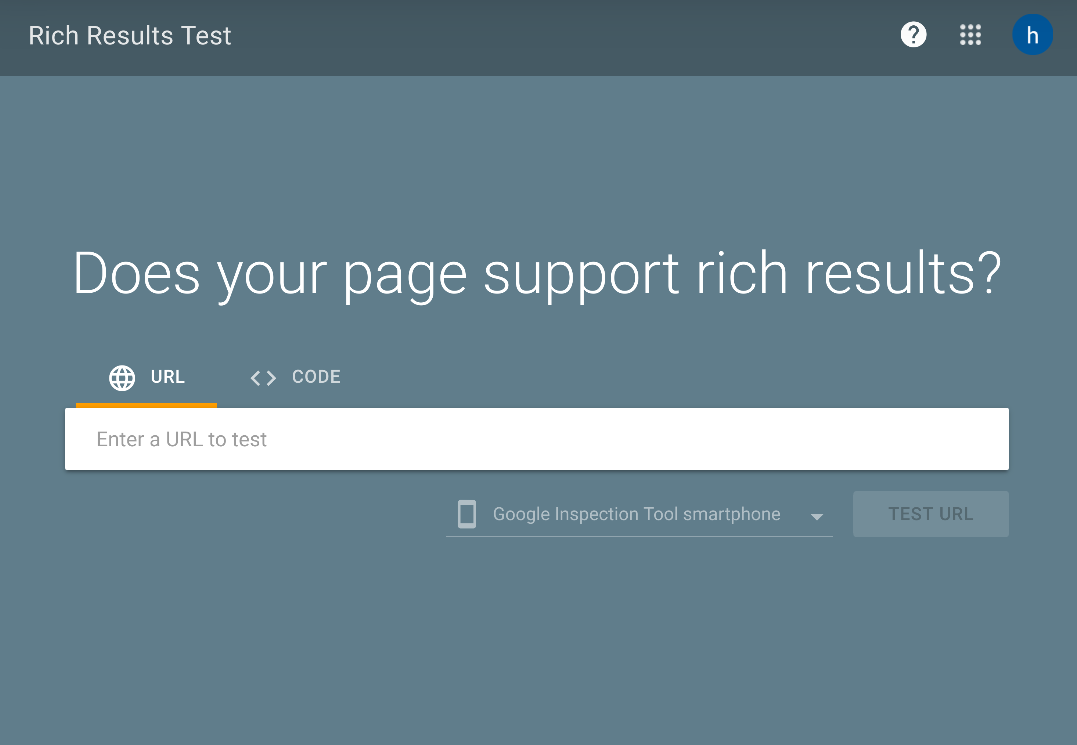
之后就能够有检测结果,我的网页没有rich-results,这并不影响什么,但是我看到它的结果是能够正常爬取
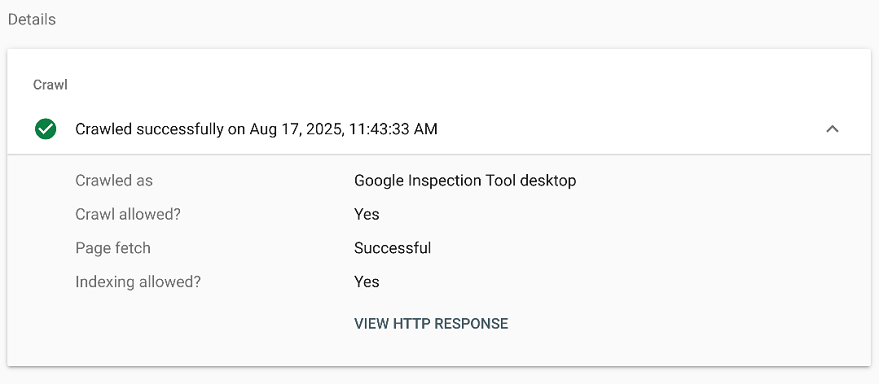
还可以查看详细页面信息,查看后可以找到抓取的代码,我原先显示的代码是
这就是设置了一个空的div容器,其内容由后面调用的markdown解析脚本自动填充容器。我就是怀疑这里会不会被爬虫渲染识别。
但是我发现,网页代码变了,变成了
<div id="aaa"><p>xxxxxxxxxxxxxxxxxxxx</p></div>
<script>generate_html_from_mdcontent("xxxxxxxxxxxxx","aaa");</script>
也就是说,它执行完成了markdown解析代码,直接生成了最后的页面内容。
我还发现多了广告展示代码,这是因为我展示了google adsense广告,并且设置自动广告展示,所以这个广告展示区域的代码自动出现了。
<ins class="adsbygoogle adsbygoogle-noablate" data-adsbygoogle-status="done" style="display: none !important;" data-ad-status="unfilled"><div id="aswift_0_host" style="border: none; height: 0px; width: 0px; margin: 0px; padding: 0px; position: relative; visibility: visible; background-color: transparent; display: inline-block;"><iframe ...></iframe></html>
这说明这个爬虫已经能够正确的渲染和抓取我的页面。
最后,还可以在详情页面查看抓取的页面截图,如果截图显示的是正常的内容,就说明google的爬虫可以正常渲染和抓取网页的页面内容。