buzz
buzz可以使用openai的whisper模型识别语音成文字。它的github地址:https://github.com/chidiwilliams/buzz
下载windows版本后安装就能用。
(buzz的运行可能需要安装ffmpeg,我的电脑本来就安装了所以就没有这一步)
whisper模型
Whisper 是一种通用的语音识别模型。它基于各种音频的大型数据集进行训练,也是一种多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
whisper的github地址:https://github.com/openai/whisper
模型的性能和参数信息
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~10x |
| base | 74 M | base.en | base | ~1 GB | ~7x |
| small | 244 M | small.en | small | ~2 GB | ~4x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
| turbo | 809 M | N/A | turbo | ~6 GB | ~8x |
buzz会自己下载模型,也可以手动下载whisper模型。下载地址,其中包含了下载文件的sha256值用于验证文件。这些模型体积越大的参数越多,识别效果也越好。
https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt
https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt
https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt
https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt
https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt
https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt
https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt
https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt
https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt
https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt
https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt
模型下载后放入buzz的默认模型目录,windows系统上是C:\Users\username\.cache\whisper\。启动buzz,在设置,模型里面能够看到已经下载的模型里面有了模型。
使用buzz识别字幕
在buzz里导入视频文件选择模型进行识别就行了,会出现进度,我使用的是medium.pt模型。
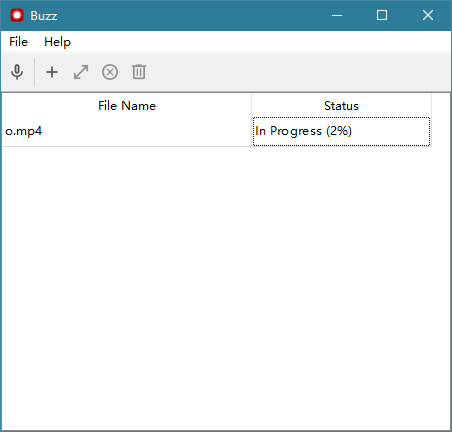
识别的是日本电影《血战冲绳岛》,2小时30分钟,识别也用了2小时30分钟。电脑是台式机,cpu是4核心8线程的i3-10105f,内存是16gb。
识别过程占用了50%的cpu,3.5gb的内存。没有使用显卡。
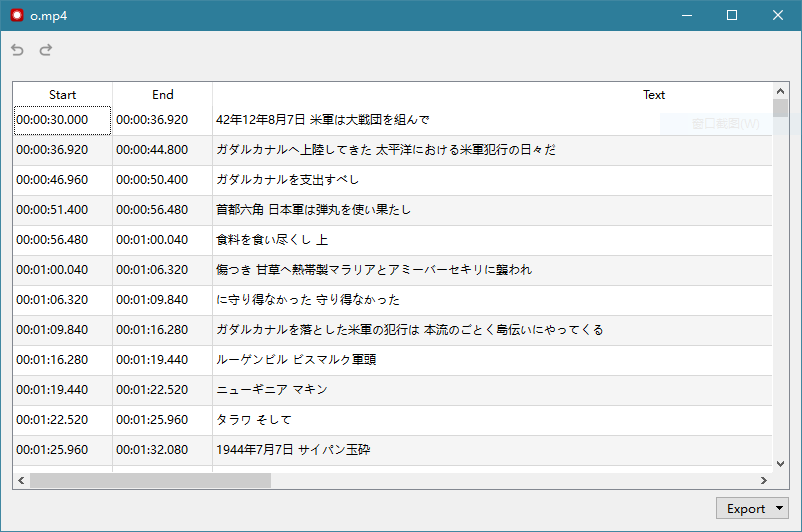
识别结果是日文字幕,可以导出成srt文件。
比较正确性
因为识别的字幕是日文,我把识别结果字幕使用软件自动翻译成了带有中文的双语字幕。我又从网上找了一个中文的正确字幕。进行一下对比。
识别后翻译的双语字幕
1
00:00:30,000 --> 00:00:36,920
1942年8月7日,美军组成大型战斗群。
42年12年8月7日 米軍は大戦団を組んで
2
00:00:36,920 --> 00:00:44,800
美军在太平洋犯下的罪行,包括登陆瓜达尔卡纳尔岛
ガダルカナルへ上陸してきた 太平洋における米軍犯行の日々だ
3
00:00:46,960 --> 00:00:50,400
瓜达尔卡纳尔岛必须被占领
ガダルカナルを支出すべし
4
00:00:51,400 --> 00:00:56,480
日军在首都六角的子弹已经用尽。
首都六角 日本軍は弾丸を使い果たし
5
00:00:56,480 --> 00:01:00,040
吃光所有的食物
食料を食い尽くし 上
6
00:01:00,040 --> 00:01:06,320
因热带疟疾和变形虫刺伤
傷つき 甘草へ熱帯製マラリアとアミーバーセキリに襲われ
7
00:01:06,320 --> 00:01:09,840
我没能保护它。我没能保护它。
に守り得なかった 守り得なかった
8
00:01:09,840 --> 00:01:16,280
美军投降瓜达尔卡纳尔岛的罪行,像主流一样传遍了岛屿。
ガダルカナルを落とした米軍の犯行は 本流のごとく島伝いにやってくる
9
00:01:16,280 --> 00:01:19,440
吕根维尔俾斯麦指挥官
ルーゲンビル ビスマルク軍頭
10
00:01:19,440 --> 00:01:22,520
新几内亚马金鸡
ニューギニア マキン
11
00:01:22,520 --> 00:01:25,960
塔拉瓦和
タラワ そして
12
00:01:25,960 --> 00:01:32,080
1944 年 7 月 7 日 - 塞班岛自杀
1944年7月7日 サイパン玉砕
13
00:01:32,080 --> 00:01:41,720
美国已经把日本的嘴堵住了,但日军大本营无法预测美国作战的走向,不知所措。
アメリカは日本の喉元に愛口を突きつけてきた しかし大本営はアメリカの作戦進路が読めなくて迷った
14
00:01:41,720 --> 00:01:47,119
是应该经过硫铁矿直接前往大陆,还是应该渡过东海登陆中国大陆?
イオトを抜いて本土に直進するか 東シナ海を横切って中国大陸に上陸するか
15
00:01:47,119 --> 00:01:51,479
但您可以在泰隆 (Tyrone) 和冲绳 (Okinawa) 之间进行选择。
するともタイロンか沖縄か ゆぜんせよ
正确的中文字幕
1
00:00:01,330 --> 00:00:11,140
这是一部以历史事实为基础的电影
一些虚构的人物和情节是为了戏剧目的而添加
2
00:00:31,090 --> 00:00:35,390
1942年8月7日
3
00:00:35,660 --> 00:00:40,930
美军组成强大的舰队从瓜达尔卡纳尔岛登陆
4
00:00:41,140 --> 00:00:46,440
这是大平洋美军反攻的开始
5
00:00:48,380 --> 00:00:51,070
我们应该死守瓜达尔卡纳尔!
6
00:00:52,710 --> 00:00:54,510
鏖战六个月之后
7
00:00:54,620 --> 00:00:59,990
日军弹尽粮绝,饥饿、伤病
8
00:01:00,220 --> 00:01:07,320
再加上热带霍乱和阿米巴红痢疾的袭击
9
00:01:07,630 --> 00:01:11,030
他们终于无法坚守
10
00:01:11,330 --> 00:01:13,860
攻陷瓜达尔卡纳尔的美军的反攻
11
00:01:14,070 --> 00:01:17,470
如洪水般沿岛袭来
12
00:01:17,770 --> 00:01:20,370
布根比尔、比斯马尔群岛
13
00:01:20,940 --> 00:01:25,440
新几内亚、马肯、塔拉瓦
14
00:01:25,680 --> 00:01:30,780
直至1944年7月7日
15
00:01:31,050 --> 00:01:33,320
塞班守军全体玉碎
16
00:01:33,590 --> 00:01:37,550
美军向日本的咽喉刺向一把匕首
17
00:01:37,860 --> 00:01:42,820
可是帝国陆军大本营却弄不清美军的下一步作战方针
18
00:01:43,260 --> 00:01:45,390
他们是夺取硫磺岛后向日本本土进攻呢?
19
00:01:45,500 --> 00:01:48,300
还是越过中国东海在中国大陆登陆呢?
20
00:01:48,470 --> 00:01:51,400
又或是从台湾呢,或许是冲绳呢?
句子是有误差的,这有语音识别的误差,也有后来用软件翻译成汉语之间的误差。总之能够看懂电影什么意思。也算可以了。使用的是medium模型,如果使用large模型识别效果会更好。