ollama下载安装
ollama的官网是:https://ollama.com/,点击下载windows版本就行了。下载完了直接安装就行了。很简单
打开cmd,输入命令ollama可以查看简单的提示
>ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
下载模型
在ollama官网能够找到模型,包括当前在国内外火热的deepseek模型,受欢迎程度已经超过了chatgpt。
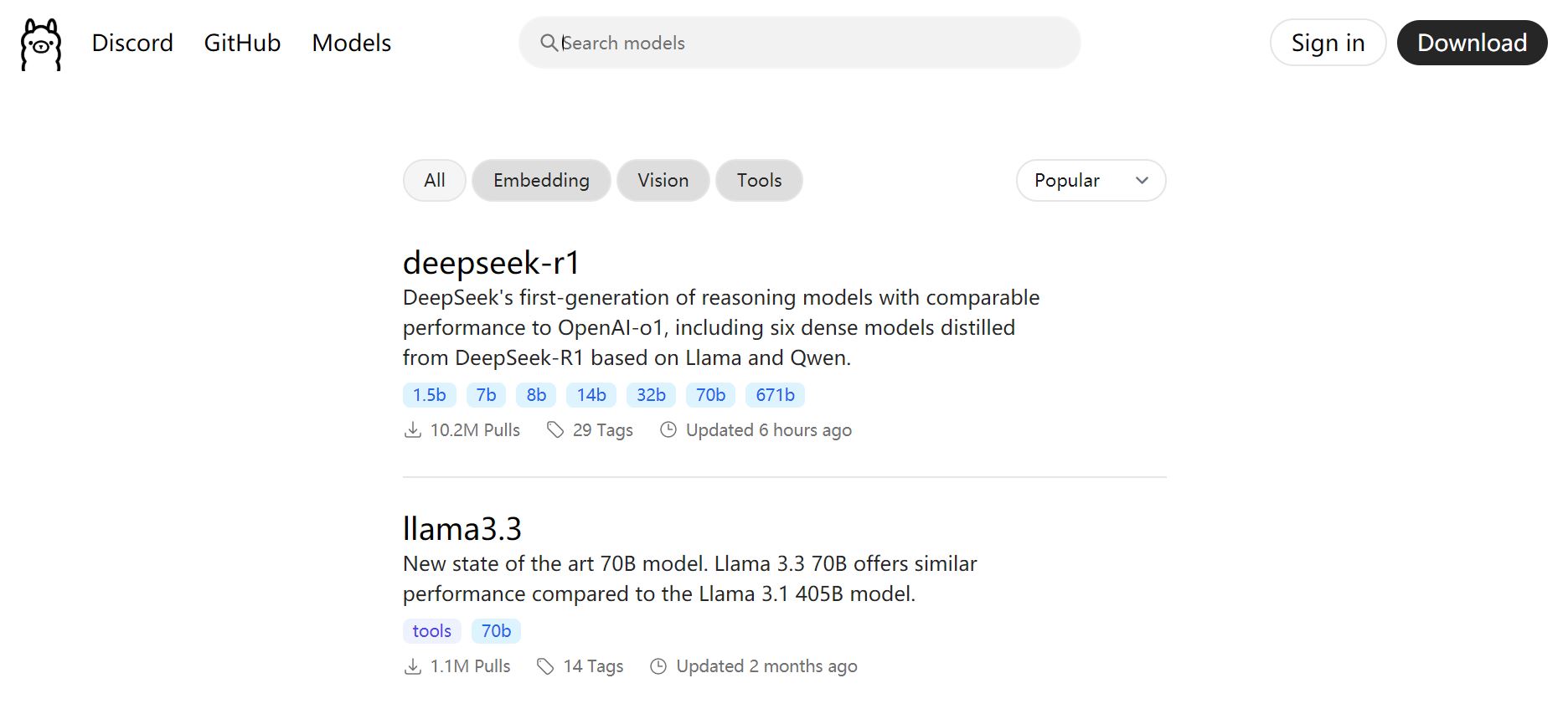
点进去可以选择模型参数量级,有1.5b,7b,8b这些,b表示"billion",即十亿。数量级越大的模型效果越好。
选择好直接复制右边的代码在cmd里面输入就行了,就能够下载和运行模型
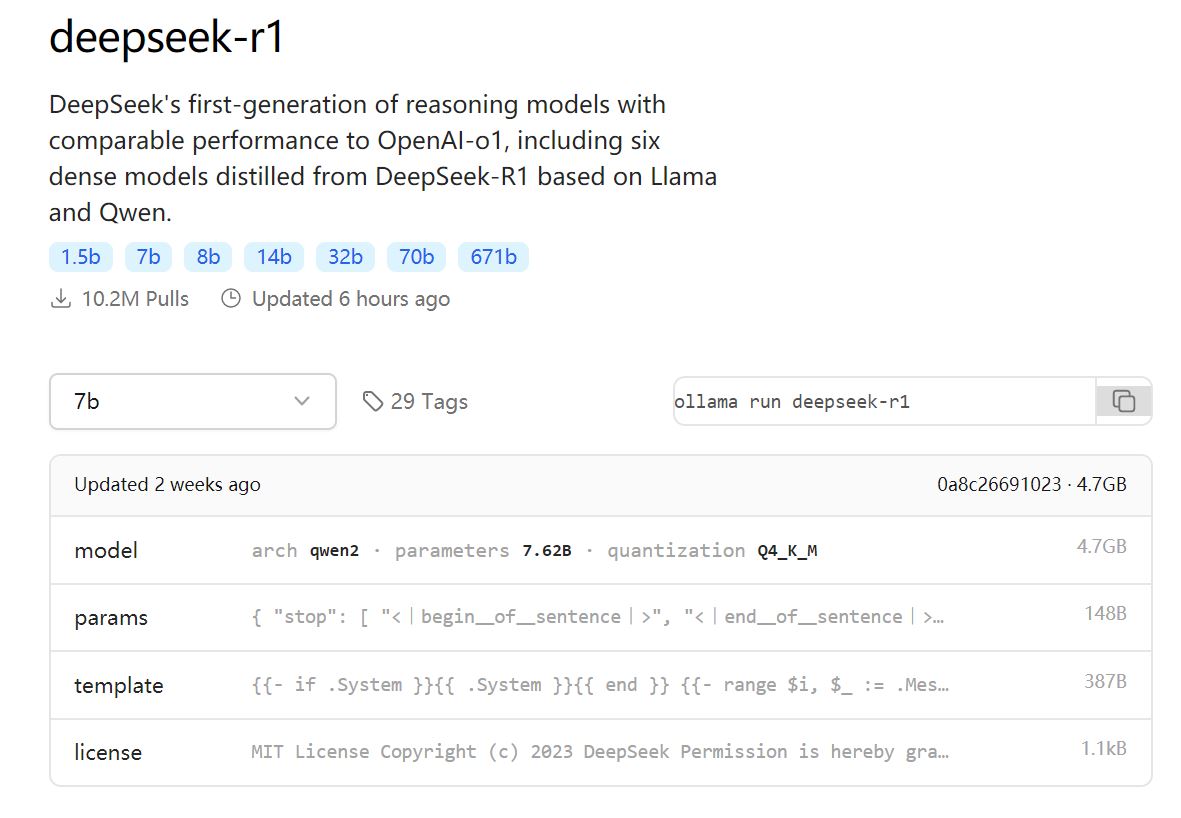
如果只是下载模型,可以使用
ollama pull deepseek-r1
模型默认是下载到Windows的C:\Users\username\.ollama\models\blobs目录下面,命名就是sha256-xxxxx这样的文件。实际上是gguf格式的模型。
通过设置windows系统的环境变量可以设置ollama的模型下载位置,服务监听地址,监听端口等,具体什么变量我就不知道了,官网文档里应该就有。
下载的问题
这个可能是连接国外服务器,所以下载慢,只有100kb/s,一会就断开,估计要下载完得重试几十次。一个模型得十几个小时下载。除非用vpn连接外网环境。我看网上也没什么解决办法。
我就想到了云主机下载。因为很多次本地下载慢的场景用云主机会改变。我尝试用它下载ollama的模型文件,在等了几秒后,开始有了速度,而且远程界面卡住,开始重连。
出现了这个情况我就知道是什么了,肯定是云主机带宽占满了,正在满速下载,没有网速给远程界面连接。我就很高兴。之前任何下载速度快了都是这样。
过了几分钟,我能连上云主机了,果然,速度达到了8MB/S。但是卡住了。我重试之后,就都下载完了,整个过程就下载了10分钟。
我是真服云主机的网络。它的网络环境和家庭宽带肯定不一样。虽然只有4M的带宽,对外上传只有450KB/S的速度,但是它对内下载不限制带宽,能够满速到10MB/S。这个模型文件直接满速下载了。而家庭宽带网络根本下载不动这个文件。
运行模型
下载完成后直接在cmd输入下面的命令就能运行模型开启对话
ollama run deepseek-r1
我电脑只有gemma模型,所以执行的是gemma模型
ollama run gemma2b
>>> who are you
I am a large language model, trained by Google. I am a conversational AI that can assist you with a wide range of
tasks, such as answering questions, providing information, and generating text. Is there anything specific I can
help you with today
>>> Send a message (/? for help)
通过在开始和结尾输入三个双引号"""可以多行输入。/bye是结束对话。
导出模型
通过把模型导出,可以在下次部署时直接本地导入模型,从而避免从网络低速下载。
列举已有的模型
ollama list
NAME ID SIZE MODIFIED
llama3:latest 365c0bd3c000 4.7 GB About an hour ago
通过下面的命令可以生成llama3模型的modelfile信息,具体要导出什么模型就指定什么模型的名字
ollama show llama3 --modelfile
把输出的modelfile信息复制,以文本格式保存到一个文件里就是一个modelfile了。其中
FROM C:\Users\Administrator\.ollama\models\blobs\sha256-6a0746a1ec1aef3e7ec53868f220ff6e389f6f8ef87a01d77c96807de94ca2aa
这部分需要根据使用时修改成模型所在路径
把这个路径的模型文件复制出来,加上后缀名.gguf,与modelfile一起保存就行了。
导入模型
首先修改modelfile文件的FROM部分,后面改成gguf模型文件的路径
使用create命令可以从modelfile文件创建模型。比如从gemma:2b的模型文件modelfile.txt导入,创建模型命名为"gemma2b"。
ollama create gemma2b -f modelfile.txt
transferring model data
using existing layer sha256:c1864a5eb19305c40519da12cc543519e48a0697ecd30e15d5ac228644957d12
creating new layer sha256:282e93491c31147e8e5e024f4bed33c5aeb847a2c1617844473fce92e1f2a29d
creating new layer sha256:a54570028ccb924daa046b9cd21a5dab677047aba1929cf9cf122f8de12894bd
creating new layer sha256:22a838ceb7fb22755a3b0ae9b4eadde629d19be1f651f73efb8c6b4e2cd0eea0
creating new layer sha256:34cdd00e989a874ba9f9ce317c02b634818b3f8f368df2028a9c82b4dd4bef7e
writing manifest
success
这样直接启动模型就行了
ollama run gemma2b
>>> hello world!
Hello World! It's great to hear from you. What can I do for you today?
>>> Send a message (/? for help)