我在源代码文件里用中文字符串常量作为一些文本显示,源代码文本是UTF-8格式,但是在GTK程序里中文还是显示不出来。提示无效UTF-8字符。
尝试下面的转换就正常,把本地编码转换成UTF8编码
gchar *tempUTF8 = g_locale_to_utf8(arg.c_str(),-1,0,0,0);
std::string ret = tempUTF8;
g_free(tempUTF8);按理说源代码就是UTF8,编译后的字符串也是UTF8,不需要转换了,为什么还要转换成UTF8才能用。
我用的是小熊猫DEVCPP这个软件,后来我检查他的编译参数发现了,它在编译时自动加了这个参数:-finput-charset=UTF-8和-fexec-charset=gbk
下面是AI的解释
-finput-charset=UTF-8 -fexec-charset=gbk 是 GCC/MinGW 编译器用于控制字符编码的两个重要参数,主要用于解决源代码文件和程序运行时字符编码的转换问题。它们的含义如下:
1. -finput-charset=UTF-8
- 作用:指定源文件的字符编码为 UTF-8。
- 用途:当你的源代码文件以 UTF-8 编码保存时(例如在 VS Code、Notepad++ 等现代编辑器中默认的编码),但编译器默认可能以其他编码(如系统本地编码)读取文件时,此选项会明确告知编译器按 UTF-8 解析源文件。
- 典型问题:如果不设置此选项且编译器默认编码非 UTF-8,源代码中的非 ASCII 字符(如中文注释或字符串)可能会被错误解析,导致乱码或编译错误。
2. -fexec-charset=gbk
- 作用:指定生成的可执行文件中字符串常量的字符编码为 GBK。
- 用途:当程序运行时,字符串常量(如
"中文")会以 GBK 编码存储在可执行文件中。这对需要兼容 Windows 默认控制台(cmd)环境的程序特别有用,因为旧版 Windows 控制台通常使用 GBK 编码而非 UTF-8。 - 典型问题:如果不设置此选项且编译器默认使用 UTF-8,输出到 cmd 的中文可能显示为乱码(因为 cmd 默认不兼容 UTF-8)。
使用场景示例
如果你的源代码是 UTF-8 编码,但需要在 Windows 的 cmd(默认 GBK)中正确显示中文,可以这样编译:
注意事项
- 终端兼容性:现代 Windows 10/11 的终端(如 Windows Terminal)已支持 UTF-8,此时可能需要调整终端编码而非强制 GBK。
- 替代方案:如果目标环境支持 UTF-8,建议直接使用
-fexec-charset=UTF-8并保持全链路 UTF-8 编码。 - 跨平台:在 Linux/macOS 下通常无需设置,因其原生采用 UTF-8。
扩展选项
-fwide-exec-charset:控制宽字符(如L"中文")的编码,例如-fwide-exec-charset=utf-16le。
通过合理配置这些参数,可以解决多平台开发中的字符编码乱码问题。
-fexec-charset=gbk会把源代码里面的字符串常量变成gbk模式,所以原本UTF8格式的字符串被替换成GBK格式,需要在代码里再转回UTF8格式。自动加的这个参数有点多此一举。但是这个IDE是面向国内开发者的,加这个参数可能也是为了方便命令行输出中文。
解决办法是去掉-fexec-charset=gbk这个参数就行了。就不用在代码里再次转换成的代码了。去掉的方法是在项目右键。项目属性,编译配置集里面,直接取消勾选【设定可执行文件的字符集为】
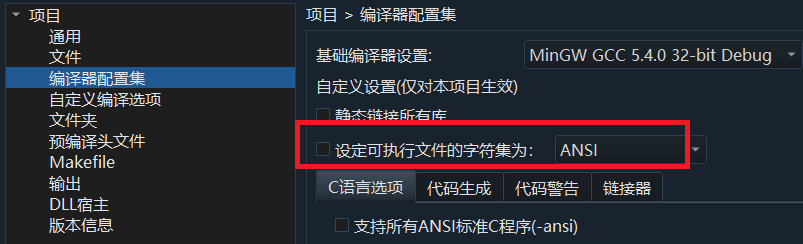
总结:
在GTK程序里,要保持统一的编码格式,源代码要是UTF8,读取的外部文件编码也要是UTF8。编译时编码参数也要是:-finput-charset=UTF-8和-fexec-charset=UTF-8.
特殊情况用g_locale_to_utf8进行非UTF8字符串转换。与windows API一起使用时,要使用现代的UNICODE宽字符Windows API,并且字符串互相需要进行UTF8<---->UNICODE(UTF-16)的转换。